Приветствую!
На официальном форуме поддержки Хрумера очень часто возникают вопросы в духе «почините Хрефер», «почему не парсит Хрефер» и т.д.
Сегодня я расскажу почему при визуальной настройке engines.ini ссылки есть — а когда ставится на парсинг, то он ничего не собирает.
Показывать я буду на примере Bing, потому что он не банит при парсинге без проксей, но методика рабочая для любой поисковой системы.
Для любителей смотреть — предлагаю видео, а для читателей мануал ниже.
Итак, открываем Тюнинг enignes.ini, в нем открываем Bing и тыкаем выполнить тестовый запрос — что убедится, что он выполняется правильно
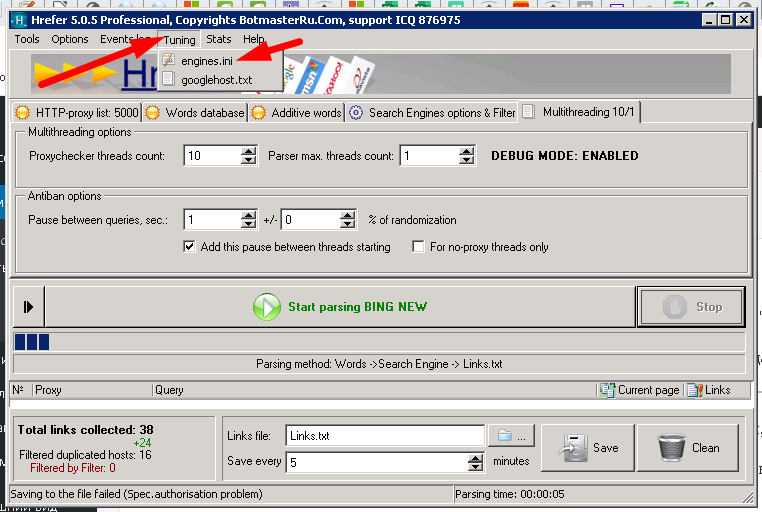
Как видно — все работает, давайте найдем посмотрим какой кусок кода из HTML source отвечает за вывод ссылок, вот он
<LI class="b_algo" data-bm="8"> <DIV class="b_title"> <H2><A href="http://www.google.de/" h="ID=SERP,5135.1">Google</A></H2> <DIV class="b_suffix b_secondaryText nowrap"><A href="http://www.microsofttranslator.com/bv.aspx?ref=SERP&br=ro&mkt=en-WW&dl=ru&lp=EN_RU&a=http%3a%2f%2fwww.google.de%2f" h="ID=SERP,5141.1">Перевести эту страницу</A></DIV></DIV> <DIV class="b_caption"> <DIV class="b_attribution" u="2|5100|4589443289778450|n_SVysn7sTMnCdie3rNTniFgmQEnvkqy"><CITE><STRONG>www.google.de</STRONG></CITE><A role="button" aria-expanded="false" aria-haspopup="true" aria-label="Действия для этого сайта" href="#"><SPAN class="c_tlbxTrg"><SPAN class="c_tlbxTrgIcn sw_ddgn"></SPAN><SPAN class="c_tlbxH" h="BASE:CACHEDPAGEDEFAULT" k="SERP,5136.1"></SPAN></SPAN></A></DIV> <P>Search the world's information, including webpages, images, videos and more. Google has many special features to help you find exactly what you're looking for.</P></DIV></LI>
А теперь закроем визуальную настройку Хрефера и в обычном режиме выставим 1 поток, при этом появится DEBUG MODE ENABLED и все данные о запросах и ответах будут логироваться в папку debug.
Если запустить парсер то в этой папке будет создан файл «GET content.txt» в который будут складывать все запросы с заголовками, и файлы вида «Query [текст запроса] Page [номер страницы].htm» в которых будет содержаться контент, который получил Хрефер. Давайте откроем любой из них и посмотрим какой кусок кода отвечает за элемент SERP, у меня вышло так.
<li class="b_algo"><div class="b_title"><h2><a href="http://www.allinoneseo.net/xrumer-services/" h="ID=SERP,5176.1">xRumer Services – All In One Seo</a></h2><div class="b_suffix b_secondaryText nowrap"><a href="http://www.microsofttranslator.com/bv.aspx?ref=SERP&br=ro&mkt=en-WW&dl=ru&lp=EN_RU&a=http%3a%2f%2fwww.allinoneseo.net%2fxrumer-services%2f" h="ID=SERP,5182.1">Перевести эту страницу</a></div></div><div class="b_caption"><div class="b_attribution" u="5|5052|4959682350089417|CG9tU-FN13jPZxLnACdYOR6GBDVqi8sT"><cite>www.allinone<strong>seo</strong>.net/<strong>xrumer 1000 </strong>-<strong>services</strong></cite><span class="c_tlbxTrg"><span class="c_tlbxH" H="BASE:CACHEDPAGEDEFAULT" K="SERP,5177.1"></span></span></div><p>FAQ: What is the turnaround time? Most reports will be sent in less than 2 days. We ask that you allow us a maximum of 6 business days to complete your order.</p></div></li>
И получается вот какая штука — в визуальном редакторе и при реальной работе — вид полученной страницы отличается.
Это связано с тем что в визуальном редакторе отображение выполняется через Internet Explorer древней версии, а реальный запрос происходит с юзер-агентом «Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0», но браузера там правда нету — обычный GET запрос.
Как следствие Internet Explorer отображает некорректный код и при обычном режиме парсинга ссылки не собираются т.к. их просто нету в коде страницы.
Итого — чтобы написать корректный шаблон, который бы парсил все что вам нужно, достаточно сделать пару запросов в дебаг режиме, отловить нужные куски кода и хоть в блокноте, хоть в редакторе engines.ini прописать нужный, давайте сделаем это для бинга. Сам запрос можно не менять, достаточно просто изменить вид маски по которой нужно собирать ссылки — Links Mask, на такую
<div class="b_title"><h2><a[...]href="[LINK]"
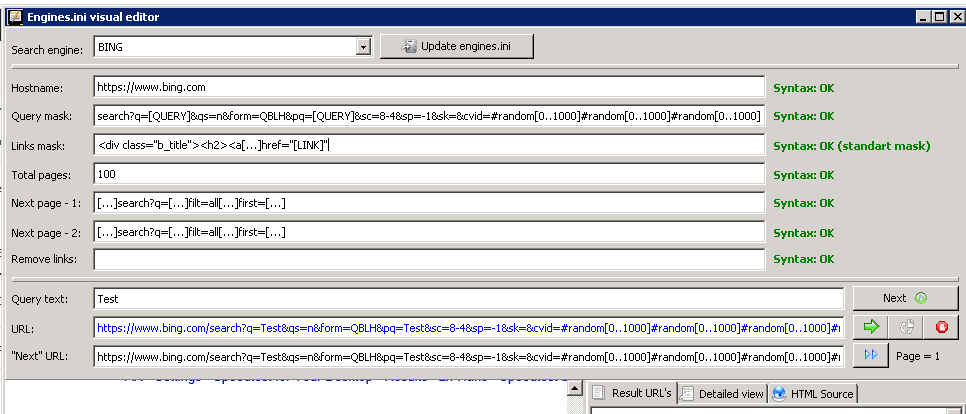
И все должно заработать, включаем парсер и вуаля — вот они ссылочки.
На этом всё, задавайте вопросы в комментариях.
Thanks for sharing.
Botmaster has a link to your tutorial.
My Hrefer is not getting any results.
I tried to modify the MASK to be
<a […] href = "[LINK]"
But when I use proxy, either socks5 or http, parsing will not work.
If I disable proxy, it can get result.
And for Next URL, mine is https://www.bing.com
Yours is a long URL
How to make hrefer Bing parsing with proxy?
Could you email me your Skype?
My email is entered below
Maybe your proxy is bad. Try to use my links masks. Also I don’t change «next» URL from the default bing template.
Привет, спасибо за статью) Очень внятно все
Можешь подсказать, у меня в папке дебаг ответы от бинга такие «Не удалось найти ни одного результата для», из меню Тюнинг все находит (запросы test xrummer), не понимаю в чем дело)
В дебаг файле есть ГЕТ запрос который идет на бинг, вот тут его видно https://youtu.be/cEgNF4txaLQ?t=92. Скопируй его и сунь в браузер, но я подозреваю что с кодировкой что-то.
Уважаемый, в режиме дебага, сохраняются только страница вида: https://prnt.sc/we7d7j
Текст там такой: Не удалось найти ни одного результата для
Кодировку крутил как мог.
Там говорят защиту какую то подцепили, сам не смотрел еще
Привет!
В тюнинге хрефера ссылки (и сама страница форума с ними) нормально отображаются, в режиме debug mode страница форума парсится в кривой кодировке. Что с этим делать? Эксперименты со сменой кодировки в хрефера не помогают
Даже не знаю честно говоря, движок у Хрефера уж больно старый — на будущем конкурсе покажу другие варианты 🙂