Приветствую!
В этом материале я расскажу как собрать сайты на движке WordPress через A-Parser с минимальным количеством мусора в виде других движков.
Кроме того такой подход можно использовать для сбора баз на любых движках.
Основной принцип сбора базы состоит в создании двух заданий —
- задание №1 парсит поисковые системы по футпринтам
- задание №2 выполняет проверку спарсенного урла на футпринты WordPress.
Если вдруг кто не знает, то футпринт это — часть кода, урла или текста на сайте, которая характеризует тот или иной тип сайта
Вообще, когда у движка уникальная структура URL или какие текстовые блоки, которые трудно изменить, то получить хороший результат можно и за один подход, например — запрос inurl:showthread в Гугл без проблем соберет форумы на SMF , потому что изменить урлы в этом движке очень сложно, а вот убрать футпринт «Powered by Simple Machines» не составляет труда и по этому запросу будет куча мусора.
Что касается WordPress, то у него нет какой то явной структуры URL к которой можно 100% привязаться при парсинге, хотя возможны варианты.
В любом случае речь идет о методике, когда 100% привязка к урлам при парсинге поисковой системы невозможна, поэтому создадим задание №1 которое спарсит сайты, которые скорее всего будут WordPress.
Задание №1 — парсинг WordPress по футпринтам
Я не стану останавливаться подробно по поводу подбора футпринтов для WordPress при парсинге, так как материал не совсем про это, поэтому я взял самый простой футпринт «Powered by WordPress» и создал обычное задание для парсинга Google.
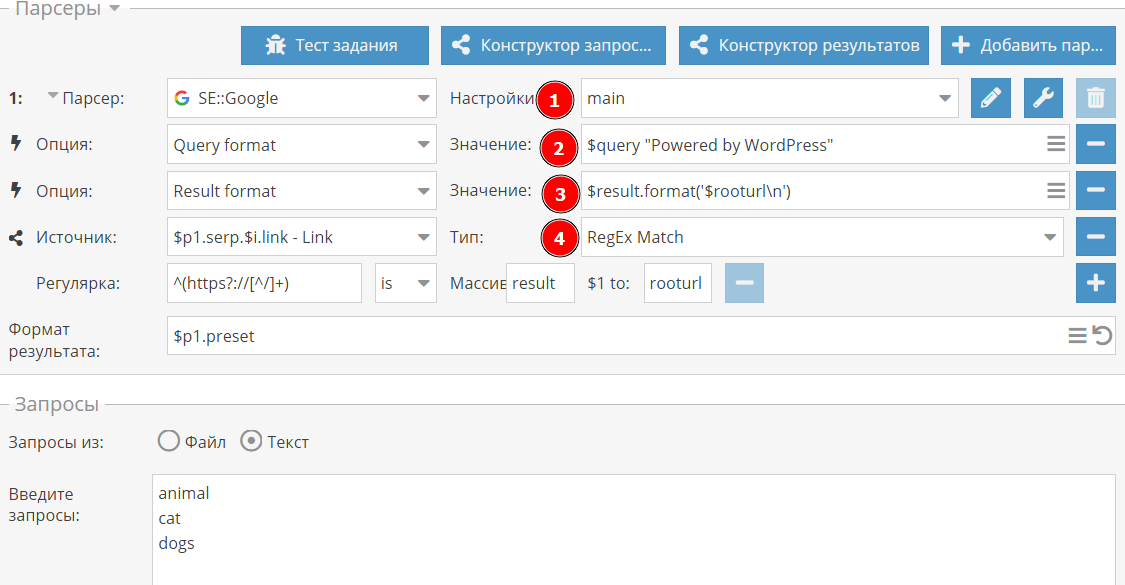
Мой пресет парсера main (1) это стандартный default, только в подключенными проксями, антикапчей и т.д. т.е. никаких особенных настроек там нету.
А вот чтоб не дописывать каждый раз к запросу футпринт, я использовал переопределение запроса (2), подробнее об этом написано в документации
Чтоб на выходе получать только корневой URL, я применил к результату регулярное выражение (3), которое его извлекает и записывает в новый массив $result, который потом и выводится (4)
Также на скрин не влезла включенная галочка «Опции: уник по строке», чтоб не получать дубликаты в результате.
При таком подходе пропустятся все WordPress которые находятся в папках, т.е. site.com/blog, но такие ситуации крайне редки, зато результат задания №2 не будет содержать дублей по доменам.
Запустив этот пресет на сбор ТОР10, мы получим ссылки главные страницы сайтов, которые могут быть WordPress, а могут быть и нет, их фильтрация будет сделана на следующем этапе.
Задание №2 — проверка спарсенного урла на футпринты WordPress.
WordPress тяжело детектится по тексту и структуре урлов, но структура папок его выдает с головой.

Поэтому если в исходном коде страницы ресурсы грузятся из папок wp-content и wp-includes, то считайте это WordPress с вероятностью 99.9% , выглядит это примерно так
<link rel='stylesheet' href='https://site.org/wp-content/themes/petlove/css/nivo-slider.css?ver=6.4.2' media='all' /> ... <script src="https://site.org/wp-content/plugins/cookie-law-info/lite/frontend/js/script.min.js?ver=3.1.7" id="cookie-law-info-js"></script> .... <script src="https://site.org//wp-includes/js/jquery/jquery.min.js?ver=3.7.1" id="jquery-core-js"></script>
Поэтому в задании №2 A-Parser зайдет на каждый УРЛ, полученный в задании №1 и проверит есть ли в исходном коде искомый текст или нет.
Сделать это можно используя парсер Net::HTTP вот с такими настройками
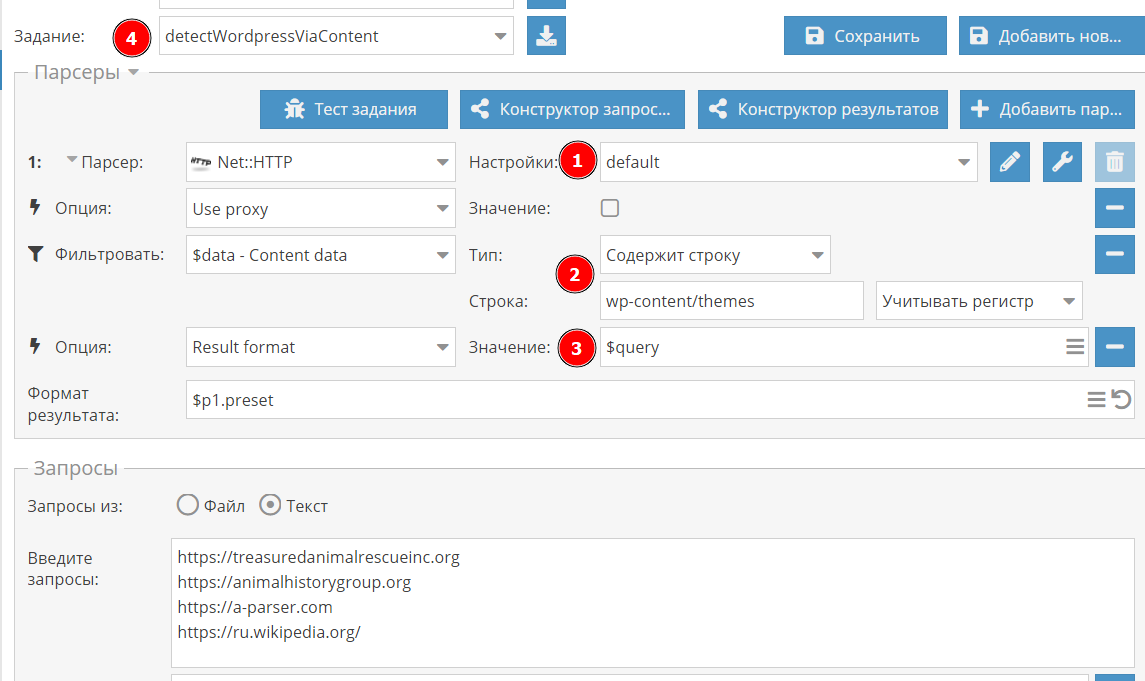
Я взял стандартные настройки и
- отключил прокси (1), это опционально, так мы будем ходить на разные сайты, то бана за частые запросы не будет
- добавил фильтр (2), который проверяет код страницы на вхождение строки wp-content/themes, если она отсутствует, то сайт не попадет в результат
- переоопределил результат, нам нужен сайт, который подавали на вход, то есть $query
- сохранил задание в отдельный пресет (4), об этом ниже.
Все, можно подавать данные на вход и проверять, парсинг будет очень быстрый, так как сайты в среднем открываются за пару секунд.
При сборе ТОР10 для трех запросов из Задания №1 из 30 полученных url — осталось 25, я проверил штуки 3 и да — это был WordPress, но тем не менее точность парсинга можно повысить еще выше.
В данном пресете A-Parser ищет просто вхождение в коде странице, а где оно будет — в подключении стилей или просто в тексте — это уже второй вопрос. Для повышения точности я рекомендую использовать несколько фильтров и/или регулярные выражения, например можно добавить такие строки для поиска просто добавив несколько фильтров.
wp-content/themes wp-content/plugins wp-includes/js/ и т.д.
Минус такого подхода — если в момент парсинга сайт будет недоступен, то в базу он тоже не попадет, также сайты с защитой Cloudflare нужно конфигурировать в пресете отдельно.
Задание №1 + 2 — обьединяем.
Остался последний штрих, чтоб не запускать задания отдельно, можно обьединить запуски в один. Для этого нужно в Задании №1 промотать в самый низ, нажать кнопку «Больше опций» и выбрать сохраненный пресет Задания №2 и поставить галочку «Использовать файл результатов для запросов». Если не разобрались, то вот ссылка на документацию
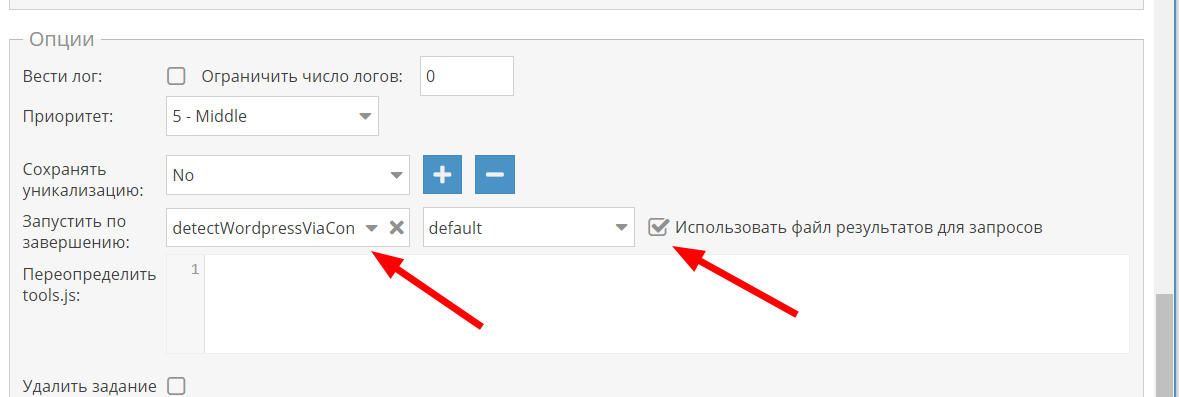
Теперь эту задачу можно запускать одним кликом.
На этом все, happy parsing.
Пресеты:
Задание №1
eJx1VN9vGzcM/lcCIUAbzHXsDduDXwrXaLoNWZ3FCfpgp4Zyxztr1kmqxLMdGP7f R0rnOzvZnu5I8cdH8iP3AmVYhzsPATCI0XwvXPwXI1ECfrM+ZznMFEIQPeGkD+DZ cC5mn0ejL9aWGuihksqI3l7giwPytRvwXuX8onKSf9TgXwrrK4mk2khds9VlVF8s xJ3dgof84vnlglMynLAQ4vD/AVMssqv1WcSk6afn9+8uvbVYe71YmHdX4vD01BPJ ItwkMOTihv2m5vZxJjfwYDmNitUdfUj6KitOFDIvHeQftu7DZS4R2PCY9aqPOw4m 81yhskbqlIzb1gF4NOpHxBzQK1OSPXdDQbjxtiI1QgwSW3QEO29aJihMHf3/Tj5i VEgdoCcCIb+RBCZ//UIT9BKtnzrGRPq9sGas9S1sQHdmMf6nWumc5jwuyOmPxvG/ TaZvYhzaEk9T0fy2njC0UaL0afpX55XbW1tS5cZS3VpVCkkOE1sbntOAlGsA1/bt K5tV1kObBn0NbXIikQPDXOkGOHad6qyKs8mcKPci2NpnlG4+6M0Fcd9FbGYtmEsN OT2UsOOBey9fotzQMj2MxPf3K0QXPo6ur+ffr59+ujq+PaQAincLLQ+4Iax4OlD8 zJpCldOG+0eUtXmgpZ2aia2cBm4p11MHuO9oOg7N/Floe/7GdRITUIAcCpkwo7U6 /DlLQZ1XhOpXRlvRCE9zNiEzqfXj/e1rNAGtm5rP3r/iTWSkkEZVUi9MJnFhchqy 4EAIpSVuU5Fce3Nq2tO0Pz04JMWLQ99HVHo5Nqi+UIBle712sFE6tnkiHWYreQ/Y ZP+F1KVOODOfvqgqsDU7/jZIzXTe7gjMsCdoEb1MexdttSWsxLgk0Zb/DjLxheXc GnyQa5jRDYtGg0SY4Ig8siTsQ9JEJkV72NEDZTco9cxphdEjZvct5OEglkIgAuag I8tYdXYG6ZZx2O74cdp0+QiCP6F90R6/VFbTbWOxoG3LY9WMNUu7N2zwTFaQrcGf 0WXFjQQTC08jEdvttl/GOfUzOmW9NKL74yB+fjskUzgfyw6yoCfps1USqRyeDFNG 6zSXkPoamtF0zWMupxrpGCPDJIOcMvD60k9YEycZJzzX5dJYAzsVMCwT7tC1/Vka A3mmQZraHRnR8uhOBiJlxw2Z4ZKaGREfDnTG/gl3ibq8ekxc0tEGJzIMD/8CFJKP kA==
Задание №2
eJx1VE1z2jAQ/S+aHtqZxDSHXnwjTJm2QzFNSHMgHDTWGlRkSdEHhPH4v3clGRtI e9Puvn37tLtSQxy1O7swYMFZkq8aouOZ5ISBg9I9K8OCy/7mdKKkA+nIDdHUWDAh YUXm4PL823K5QD+DinqBiIa4owZkUXswhjPAIGdoewvaqLcj2nsqPEIqKiy0Q0bF hQODcawauFAJdRTtFFgmVIlaKJcDDTno2zIJHLkt1GAxprTjSmLQgrSk/b+sSpma uq7iwPnh1YM5vkjSrtcnQXYasSGq77KuXX3wke5hqdI1YHBP0ZrTOnLidSBEs1T0 46fMvQUGyhgPcqlIFUJ7h6pPkr9GTVIhNujiYKdG1ehyEAmi2JO6VSeeIIWPub9S Dsmd8XBDLCqdUtTB+kAcBXYE20ydMkXsHvobouRYiBnsQQywSH/vuWC4CuMKk753 if+GFO842v5256VwNAeDGnqWaN0XP4cspmZqc+qF4DV3aNuJ8jLM5TM6dwC6b9k8 wGploC+TWtAVx/XXIMMaDAMb68F1cYuLoVw6cf0qvim61TohvVziGyvkRNVaQLhW 4MR38DCsxth2MwhGf+93qZNYIL7N7p0Rp5SwPx4TqTYcV+9LkFdjG89rdpQlFeLp YXatxjqlC/nVmKvZxa0gW+e0zUcjfB/UegOMSl5TgT0oPXBZZspsXuQJlYJbjpzm uDHK66v4bfo9slLVg9f47MB3XAPjNOBHJIh1sEGS0Mh23f86/W/VnP09edPiXvyx i4QJfQwI9OE4bPwE7tq/osq/Xg==
15 thoughts on “Как спарсить WordPress сайты (и не только) через A-Parser”